이번에는 미뤄뒀던 파티클 필터를 공부해봤습니다. 이 글의 목적은 파티클 필터의 원리를 누구나 이해할 수 있도록 상세히 설명하는 것입니다.
인터넷을 찾아보면 논문을 포함하여 파티클 필터에 대해 상세히 설명해놓은 글은 수도 없이 많습니다. 그러나 쉽게 설명해놓은 글들은 중요한 개념들을 증명 없이 추상적인 비유로만 설명하고 있습니다. 그렇게 되면 코드로 구현하는 것은 쉬울지라도 그것이 왜 동작하거나 동작하지 않는지, 알고리즘을 변형해도 수학적으로 최적을 보장하는지 알기 어렵습니다.
반대로 논문처럼 내용을 구체적으로 설명한 글들은 대부분 쉬운 부분을 설명하지 않고 넘어갑니다. 그런데 그 쉬운 부분이라는 것이 식의 전개나 인수분해 수준이 아니라 여러가지 복잡한 정리를 적용해야 증명할 수 있어 그 흐름을 이해하기가 어려운 경우가 많았습니다. 더군다나 위키피디아와 논문을 포함한 상당수의 글들은 다양한 표기법들을 설명 없이 사용하고 있어 애초에 식의 올바른 의미를 해석하는 것조차 어렵습니다.
그래서 고등학생 정도의 수학적 지식만 가지고 있는 사람도 이해할 수 있도록, 그러나 추상적인 개념뿐만이 아니라 엄밀한 수학적 증명까지 포함하여 파티클 필터에 대해 설명하고자 합니다.
구체적으로 다음과 같은 배경 지식이 필요합니다.
- 고등학교 수준의 확률론 (조건부 확률, 결합확률, 베이즈 정리)
- 적분의 개념
내용이 길기 때문에 문어체로 정리합니다.
필터(Filter)
파티클 필터를 포함한 다양한 필터를 이해하기 위해서는 먼저 필터의 개념을 파악하는 것이 필수적이다. 신호처리 및 제어공학에서 필터란 다양한 신호가 중첩된 신호에서 원하는 신호만을 통과시키는 장치나 그런 수학적인 구조를 뜻한다.
필터가 필요한 이유는 신호에는 필연적으로 잡음이 포함되기 때문이다. 제어나 신호처리의 관점에서는 모든 신호를 원하는 신호와 잡음의 합으로 간주한다. 신호가 손실 없이 전달되는 이상적인 환경에서는 필터가 불필요하겠으나 실제로는 측정의 불확실성을 포함한 여러 원인으로 잡음이 포함되므로 필터가 필요하다.
필터의 동작은 근본적으로 신호의 값을 얻는 과정과 이로부터 참값을 어림하는 과정으로 나뉜다. 이때 신호의 값을 얻는 것을 측정(measurement) 또는 관측(observation) 이라고 하며, 이로부터 참값을 어림하는 것을 추정(estimate) 또는 예측(prediction) 이라고 한다.
신호의 특성에 따라 필터는 다양한 방법으로 구현된다. 예를 들어 전자공학에는 주로 신호와 잡음의 주파수가 다르다. 이로부터 원하는 주파수 대역을 제외한 나머지를 감쇄시키는 방법으로 필터를 구현하게 된다. 그 중 가장 기본적인 것은 이동평균이다. 이동평균은 이전의 측정값들의 (가중)평균으로부터 현재 시점의 참값을 추정하는 것으로, 이는 주파수 영역에서는 고주파 신호를 감쇄시키는 것으로 볼 수 있다.
반면 시스템이 복잡하거나 비선형성이 커서 이러한 방법으로는 신호와 잡음을 구분하기 힘든 경우가 있다. 그런 경우 확률론에 기반한 필터를 사용할 수 있다. 확률적 필터는 신호의 단일 참값을 추정하기보다는 신호의 확률분포를 구하는 방식으로 접근한다. 이것은 수학적으로는 아래와 같이 현재 시점까지의 측정값들이 주어질 때 참값의 조건부 확률분포로 표현된다.
p(xt∣zt,zt−1,⋯,z0)
확률분포 안에서 콤마 ,가 사용된 경우 결합확률분포 (a∩b)를 의미한다. 그러므로 위 식은 아래와 같이 해석하면 된다.
p(xt∣zt,zt−1,⋯,z0)=p(xt∣zt∩zt−1∩⋯∩z0)=p(xt∩zt∩zt−1∩⋯∩z0)/p(zt∩zt−1∩⋯∩z0)
베이즈 필터(Bayes Filter)
베이즈 필터란 이미 알고 있는 다른 확률분포들을 조합하여 위 확률분포를 표현하는 방법이다. 왜냐하면 위 식은 단순히 '측정값들이 주어질 때 참값의 확률분포'라는 문장을 수학적으로 표현한 것일 뿐이며, 그 확률분포를 계산하는 방법은 전혀 알려주지 않기 때문이다.
베이즈 필터에서는 아래 두 확률분포를 이미 알고 있다고 가정한다.
- p(zt∣xt): 참값이 주어졌을 때 측정값의 확률분포
- p(xt∣xt−1): 이전 참값이 주어졌을 때 참값의 확률분포
이 두 확률분포를 각각 측정 모델(measurement model) 과 시스템 모델(system model) 이라고 하며 이 두 확률분포를 이용하여 참값의 확률분포를 다음과 같이 재귀적으로 계산할 수 있다.
p(xt∣zt−1,zt−2,⋯,z0)=∫p(xt∣xt−1)p(xt−1∣zt−1,zt−2,⋯,z0)dxt−1
p(xt∣zt,zt−1,⋯,z0)=∫p(zt∣xt)p(xt∣zt−1,zt−2,⋯,z0)dxtp(zt∣xt)p(xt∣zt−1,zt−2,⋯,z0)
아래에서는 베이즈 필터를 유도하기 위해 필요한 다른 개념들을 설명하고 이로부터 베이즈 필터를 유도한다.
조건부 독립(Conditional Independence)
베이즈 필터의 유도에는 조건부 독립의 개념이 많이 사용되므로 조건부 독립을 이해하는 것이 중요하다. 조건부 독립이란 어떤 사건 A가 주어졌을 때 사건 B와 C가 독립이라는 것을 의미한다. 아래는 조건부 독립에 대한 다양한 표현이며, 이는 모두 동치이다.
- p(B,C∣A)=p(B∣A)p(C∣A): A가 주어졌을 때 B와 C의 결합확률분포는 B와 C의 확률분포의 곱과 같다.
- p(A∩B∩C)=p(A∩B)p(A∩C)/P(A): 위 식을 조건부 확률의 정의에 따라 전개한 것
- p(B∣A,C)=p(B∣A): A가 주어졌을 때 B의 확률분포는 C에 영향을 받지 않는다.
- p(C∣A,B)=p(C∣A): A가 주어졌을 때 C의 확률분포는 B에 영향을 받지 않는다.
이때 중요한 것은 B와 C가 독립이라는 것은 A가 주어졌을 때에만 성립한다는 것이다. 즉, B와 C가 A에 대하여 조건부 독립인 경우 일반적으로 B와 C는 독립이 아니다.
또한 두 변수 A,B가 다른 변수 C에 대해 조건부 독립인 경우 다음과 같은 중요한 성질이 성립한다.
p(A∣B)=∫p(A∣C)p(C∣B)dC
이 방정식을 Chapman–Kolmogorov Equation (CKE)라고 한다. 좀 더 정확히는 CKE는 여러 확률변수에 대한 좀 더 일반적인 방정식을 말하는 것이며 위 방정식은 3개의 확률 변수를 다루는 CKE의 특수한 경우라고 할 수 있다.
증명은 다음과 같다.
A와 B가 C에 대해 조건부 독립이므로
p(A∣C)=p(A∣B,C)
이것을 위 식에 대입하면
p(A∣B)=∫p(A∣B,C)p(C∣B)dC
우변을 조건부 확률의 정의에 따라 전개하면
=∫p(B∩C)p(A∩B∩C)p(B)p(C∩B)dC
=∫p(B)p(A∩B∩C)dC
전체 확률의 법칙(law of total probability)에 의해
=p(B)p(A∩B)
조건부 확률의 정의에 의해
=p(A∣B)
마르코프 체인(Markov Chain)
어떠한 시스템이 다음과 같은 성질을 만족할 때 이 시스템을 마르코프 체인이라고 한다.
p(xt∣xt−1,xt−2,⋯,x0)=p(xt∣xt−1)
이는 시스템의 현재 상태가 그 직전의 상태에만 의존하고 다른 과거의 상태들에는 의존하지 않는다는 것을 나타낸다. 현실의 물리 현상을 포함한 많은 시스템이 이러한 성질을 만족한다.
마르코프 체인은 조건부 독립의 관점에서 해석할 수 있다. 즉, xt−1가 주어졌을 때 xt의 확률분포는 xt−2,⋯,x0에 대해 조건부 독립이다.
은닉 마르코프 체인(Hidden Markov Chain)
그러나 일반적으로는 시스템의 전체 상태를 직접 측정하는 것은 불가능하며 시스템의 일부분을 간접적으로만 측정할 수 있다. 이러한 마르코프 체인을 은닉 마르코프 체인(hidden Markov chain) 이라고 한다.
X0↓Z0→X1↓Z1→X2↓Z2→X3↓Z3→⋯⋯⋯signalobservation
위 도식에서 화살표 X는 상태이며 직접 측정이 불가능하다. Z는 측정을 통해 얻어진 관측값이다. 화살표 A→B는 확률변수 B가 오직 A에만 의존한다는 것을 나타낸다. 이는 A가 아닌 임의의 확률변수 C에 대하여 B와 C는 A에 대한 조건부 독립이 된다는 의미로도 해석할 수 있다.
베이즈 정리(Bayes' theorem)
베이즈 정리란 조건부 확률에 대하여 아래 관계가 성립한다는 것을 말한다.
p(A∣B)=p(B)p(B∣A)p(A)
베이즈 정리는 다음과 같은 두 가지 방법으로 해석할 수 있다.
- 역확률 문제: P(B∣A)가 주어졌을 때 P(A∣B)를 구하는 것
- 예) 병에 걸렸을 때 양성반응을 보이는 확률이 주어졌을 때, 반대로 양성반응을 보였을 때 병에 걸려있을 확률을 구하는 것
- 사후 확률 추정: 사전확률 P(A)를 측정값 B를 통해 더 정확한 확률로 업데이트하는 것
- 예) 일반적으로 어떤 병에 걸릴 확률을 알고 있었는데 검사 결과를 새롭게 알게 되었을 때 병에 걸릴 확률을 다시 계산하는 것
베이즈 필터는 사후확률 추정의 관점에서 베이즈 정리를 사용한다. 즉, 기존에 알고 있던 확률분포에 측정값을 반영해 더 정확한 확률분포로 업데이트하는 것을 반복한다.
베이즈 필터의 유도
구하고자 하는 확률분포를 다시 상기해보면 다음과 같다.
p(xt∣zt,zt−1,⋯,z0)
이것을 계산하기 위해 아래와 같은 두 확률분포를 알고 있다고 가정한다.
- p(xt∣xt−1): 시스템 모델
- p(zt∣xt): 측정 모델
이로부터 다음과 같이 베이즈 정리를 적용하여 베이즈 필터를 유도한다.
먼저 구하고자 하는 식에 그대로 베이즈 정리를 적용하면
p(xt∣zt,zt−1,⋯,z0)=p(zt,zt−1,⋯,z0)p(zt,zt−1,⋯,z0∣xt)p(xt)
이때 zt는 은닉 마르코프 체인의 가정에 따라 오직 xt에만 의존하므로 xt가 아닌 임의의 확률변수 k에 대해 조건부 독립이다. 즉, 다음이 성립한다.
∀k=xt,p(zt,k∣xt)=p(zt∣xt)p(k∣xt)
이로부터 k=zt−1,zt−2,⋯,z0로 두면
p(zt,zt−1,⋯,z0∣xt)=p(zt∣xt)p(zt−1,zt−2,⋯,z0∣xt)
이것을 다시 베이즈 정리에 적용하면
=p(zt,zt−1,⋯,z0)p(zt∣xt)p(zt−1,zt−2,⋯,z0∣xt)p(xt)
그런데 조건부 확률의 정의에 따라 p(zt−1,zt−2,⋯,z0∣xt)p(xt)=p(zt−1,zt−2,⋯,z0,xt)이므로
=p(zt,zt−1,⋯,z0)p(zt∣xt)p(zt−1,zt−2,⋯,z0,xt)
분모와 분자를 각각 p(zt−1,zt−2,⋯,z0)으로 나누면
=p(zt∣zt−1,zt−2,⋯,z0)p(zt∣xt)p(xt∣zt−1,zt−2,⋯,z0)
이때 분모 p(zt∣zt−1,zt−2,⋯,z0)은 앞서 조건부 독립 섹션에서 다뤘던 CKE에 의해 다음과 같이 분해된다.
p(zt∣zt−1,zt−2,⋯,z0)=∫p(zt∣xt)p(xt∣zt−1,zt−2,⋯,z0)dxt
이것을 다시 식에 대입하면 다음을 얻는다.
p(xt∣zt,zt−1,⋯,z0)=∫p(zt∣xt)p(xt∣zt−1,zt−2,⋯,z0)dxtp(zt∣xt)p(xt∣zt−1,zt−2,⋯,z0)
이 식에서 알지 못하는 부분은 p(xt∣zt−1,zt−2,⋯,z0)이다. 이때 마르코프 모델의 가정에 따라 xt는 오직 xt−1에만 의존하므로 xt는 zt−1,zt−2,⋯,z0과 조건부 독립이다. 따라서 마찬가지로 CKE에 의하여 다음과 같이 분해된다.
p(xt∣zt−1,zt−2,⋯,z0)=∫p(xt∣xt−1)p(xt−1∣zt−1,zt−2,⋯,z0)dxt−1
이때 이 식에서 모르는 부분인 p(xt−1∣zt−1,zt−2,⋯,z0)은 원래 구하고자 했던 식 p(xt∣zt,zt−1,⋯,z0)에서 첨자만 하나 줄어든 형태이다. 이로부터 다음과 같은 재귀적인 추정을 수행할 수 있다.
- p(xt−1∣zt−1,zt−2,⋯,z0)를 알고 있다고 가정한다.
- 이로부터 p(xt∣zt−1,zt−2,⋯,z0)를 계산한다. 이것은 t−1 시점까지의 정보를 바탕으로 t 시점의 참값의 확률분포를 계산하는 것이므로 이 과정을 추정 또는 예측 (prediction)이라고 한다.
- 이로부터 p(xt∣zt,zt−1,⋯,z0)를 계산한다. 이것은 추정값에 새로운 측정값을 반영하여 참값의 확률분포를 재계산하는 것이므로 이 과정을 업데이트 (update)라고 한다.
처음 계산을 시작할 때는 초기 추정값 p(x0)이 필요하다. p(x0)은 아무런 정보도 없는 경우의 확률분포이므로 균등확률분포나 정규분포 등을 사용할 수 있으며 더 정밀한 초기 추정값을 사용할수록 이후 추정이 정확해진다.
위와 같이 참값의 확률분포를 추정하는 방식을 베이즈 필터라고 하며 모든 확률적 필터링의 이론적 기반이 된다.
그런데 베이즈 필터는 예측 과정에서 적분을 수행해야 하는데, 비선형이거나 수치적으로 정의된 함수의 적분은 매우 어렵거나 때로는 불가능한 경우가 많다. 따라서 일반적으로는 베이즈 필터를 곧바로 현실의 문제에 적용할 수 없으며 이를 근사하는 다양한 방법들이 제시되었다.
임의의 확률분포를 근사하는 방법은 크게 모수적 방법 (parametric method) 과 비모수적 방법(nonparametric method) 으로 나뉜다. 모수적 방법은 확률분포가 특정한 형태의 확률분포를 따른다고 가정하고 그 모델의 파라매터를 추정하는 방법이다. 이것은 확률분포에 대한 이론적인 근거가 있을 때 사용할 수 있다. 반면 비모수적 방법은 확률분포에 대한 어떠한 가정도 하지 않고 측정값들을 이용하여 확률분포를 근사하는 방법이다.
칼만 필터는 베이즈 필터에 대한 모수적 방법을 통한 근사로, 각 모델의 선형성과 오차가 정규분포임을 가정하여 적분을 해석적으로 풀 수 있도록 하는 방법이다. 칼만 필터는 계산량이 크지 않고 선형성과 정규분포 가정이 만족되는 경우에는 매우 정확한 추정을 제공한다. 그러나 선형성과 같은 중요한 가정이 만족되지 않는 경우에는 필터가 발산할 수 있다.
이후에 다룰 파티클 필터는 베이즈 필터에 대한 비모수적 방법을 통한 근사로 몬테 카를로 샘플링을 이용하여 베이즈 필터를 근사하는 방법이다. 파티클 필터는 모델에 대한 가정이 없으며, 따라서 선형성과 같은 가정이 만족되지 않는 경우에도 사용할 수 있다. 그러나 샘플링을 통한 근사이므로 계산량이 크고 정확도가 낮을 수 있다는 단점이 있다.
파티클 필터(Particle Filter)
앞서 베이즈 필터는 다음과 같은 두 단계의 반복으로 참값의 확률분포를 추정한다고 하였다.
- 예측
p(xt∣zt−1,zt−2,⋯,z0)=∫p(xt∣xt−1)p(xt−1∣zt−1,zt−2,⋯,z0)dxt−1
- 업데이트
p(xt∣zt,zt−1,⋯,z0)=∫p(zt∣xt)p(xt∣zt−1,zt−2,⋯,z0)dxtp(zt∣xt)p(xt∣zt−1,zt−2,⋯,z0)
그런데 일반적으로 시스템은 2차원 이상의 벡터이며 시스템 모델은 행렬방정식으로 주어진다. 그러므로 예측 단계의 적분은 고차원에서의 다중 적분이 되며 적분 영역도 대단히 복잡해질 수 있다.
경험적 분포 함수(Empirical Distribution Function)
이런 경우 경험적 분포 함수(empirical distribution function)를 이용하여 적분을 근사할 수 있다. 경험적 분포 함수는 어떤 확률분포함수의 값을 직접 구하기는 어렵지만 샘플링하는 것은 쉬운 경우 그 측정값들을 샘플링하여 이를 통해 확률분포를 근사하는 방법이다. 이때 샘플의 개수가 충분히 많아지면 샘플들의 분포는 원래 확률분포에 수렴하게 된다. 이를 수학적으로는 아래와 같이 표현할 수 있다.
p^(x):=n1i=1∑nδ(x−xi)≈p(x)
이때 xi는 확률분포 p(x)로부터 샘플링한 값이고 δ(x−xi)는 Dirac-delta 함수로 δ(0)=∞이고 δ(x)=0 (x=0)이다. Dirac-delta 함수의 적분은 1이 된다. 또는 아래와 같이 위 식을 적분하여 누적분포함수의 형태로 표현할 수도 있다.
F^(x)=n1i=1∑n1xi≤x≈F(x)
이때 1xi≤x는 xi≤x일 때 1, 그렇지 않으면 0인 함수이다.
아래는 정규분포로부터 샘플링한 샘플들로 경험적 분포함수를 계산한 것이다. 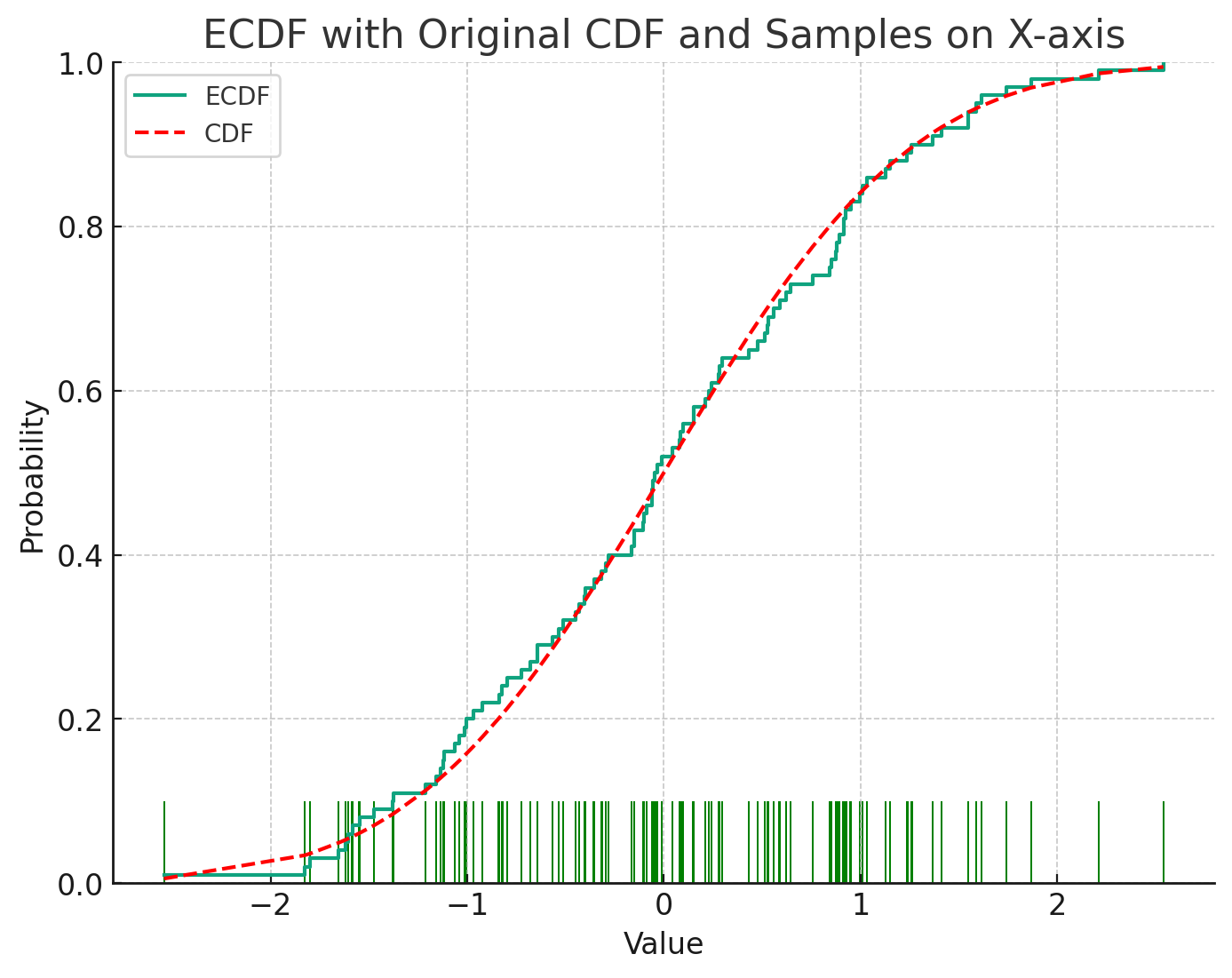
중요도 샘플링(Importance Sampling)
그런데 경험적 분포함수를 현실에서의 실험이 아니라 시뮬레이션을 통해 구하기 위해서는 원래 확률분포를 알고 있어야 한다는 문제가 있다. 즉, 확률분포를 구하기 위해서 경험적 샘플링을 사용하려고 했는데 그러려면 원래 확률분포를 알고 있어야 된다는 역설적인 문제가 발생한다.
이때 원래 확률분포에서 샘플링이 불가능하더라도 중요도 샘플링(importance sampling)을 사용하면 샘플링을 통해 확률분포를 근사할 수 있다. 중요도 샘플링은 다음과 같이 확률분포 p(x)를 알지 못하더라도 다른 확률분포 q(x)로부터 샘플링하여 이를 이용하여 p(x)의 기대값을 근사하는 방법이다.
Ep[f(x)]=∫f(x)p(x)dx=∫f(x)q(x)p(x)q(x)dx≈n1i=1∑nf(xi)q(xi)p(xi)
아래는 균등확률분포로부터 중요도 샘플링을 사용하여 정규분포의 누적확률밀도함수를 근사한 것이다.
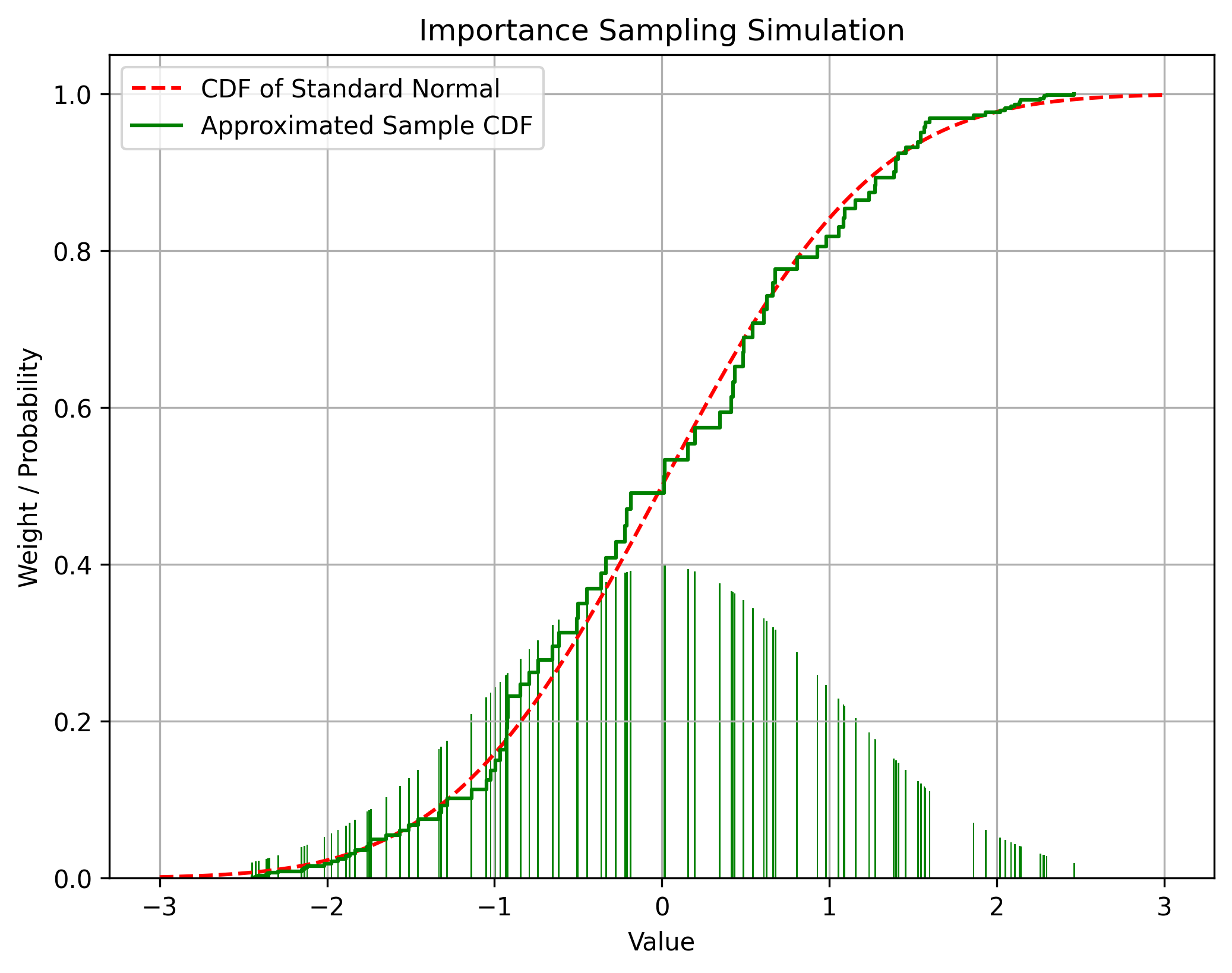
이때 샘플링을 수행하는 확률분포 q(x)를 중요도 분포(importance distribution) 또는 제안 분포(proposal distribution)라고 한다. 제안 분포는 원래 분포의 확률밀도가 0보다 큰 곳에서 0이 아닌 값을 가지는 임의의 확률분포를 선택할 수 있으나, 원래 분포화 유사할수록 근사의 정확도가 높아진다. 제안 분포는 일반적으로 샘플링하기 쉬운 정규분포나 균등분포 등을 사용한다.
다만 중요도 샘플링의 결과로 얻어진 확률분포는 그 평균은 원래 확률분포에 수렴하지만 그 분산은 원래 확률분포와 다르다는 것을 유의해야 한다.
순차 중요도 샘플링(Sequential Importance Sampling)
파티클 필터는 앞서 언급한 것처럼 중요도 샘플링을 사용하여 베이즈 필터를 근사한다. 이것을 순차 중요도 샘플링 (Sequential Importance Sampling; SIS)라고 한다. SIS의 증명은 약간 복잡하다. 먼저 각 입자가 시간이 흐름에 따라 특정한 확률분포를 따라 움직일 때, 그 궤적 자체의 확률분포를 구한 후 그것이 또한 입자의 확률분포와 같음을 보일 것이다.
일반적으로 다른 글들을 보면 이 계산에서는 제안 확률분포를 전부 q라는 하나의 기호로 표기한다. 그러나 이 글에서는 혼동을 피하기 위해 서로 다른 확률분포에는 서로 다른 기호를 할당할 것이다. 기호 p는 일반적으로 어떤 확률변수의 확률분포를 나타내는 것이며, 그 외 다른 기호들은 특정한 확률분포를 나타내는 것이다. 이들을 혼동해서는 안 된다.
입자 궤적의 확률분포
먼저 초기 확률분포 q0(x)로부터 n개의 샘플 x0(1),x0(2),⋯,x0(n)을 추출한다. 자명히 p(x0)=q0(x)이다.
그리고 각 입자 x0(i)가 시간의 흐름에 따라 rt(i)(xt+1(i))라는 확률분포를 따라 이동한다고 하자.
입자가 그 다음 순간에 있을 위치는 일반적으로 그 이전 순간에 있었던 위치에 의존한다. 그러므로 명시적으로 표시되지는 않았지만 rt(i)(xt+1(i))는 일반적으로 xt(i)에 종속이다.
그렇다면 각 입자 x(i)에 대하여, 입자가 처음에 x0(i)에 있고, 그 다음 순간에는 x1(i)에 있을 확률은 다음과 같다.
p(x1(i),x0(i))=q0(x0(i))r0(i)(x1(i))
확장하면, 각 입자가 시간에 따라 궤적 x0(i),x1(i),⋯,xt(i)를 따라 움직일 확률은 다음과 같다.
p(xt(i),xt−1(i),⋯,x0(i))=q0(x0(i))r0(i)(x1(i))r1(i)(x2(i))⋯rt−1(i)(xt(i))
이때 시간 t에서 입자 궤적의 확률분포를 qt라고 하자. 그러면 qt는 다음과 같이 표현된다.
qt(x0(i),x1(i),⋯,xt(i))=q0(x0(i))r0(i)(x1(i))r1(i)(x2(i))⋯rt−1(i)(xt(i))
이것을 점화식 형태로 표현하면 다음과 같다.
qt(x0(i),x1(i),⋯,xt(i))=qt−1(x0(i),x1(i),⋯,xt−1(i))rt−1(i)(xt(i))(1)
이것이 각 입자가 시간에 따라 특정한 궤적을 따라 움직일 확률분포다.
상태 궤적의 확률분포
다음으로 우리가 얻고자 하는, 원래 상태의 확률분포는 다음과 같다.
p(x0,x1,⋯,xt∣z0,z1,⋯,zt)
이것은 앞에서 다뤘던 확률분포들과는 약간 다르다. 앞에서는 현재 시점까지의 관측값들이 주어졌을 때 현재 상태의 확률분포를 다뤘다. 그러나 이것은 현재 시점까지의 관측값들이 주어졌을 때 이전 시점 상태들의 확률분포를 모두 포함한다.
이때 적절한 가중치 wt(i)가 있어서 중요도 샘플링의 원리에 따라 입자의 확률분포가 구하고자 하는 확률분포를 근사한다고 가정하자. 즉, 아래 조건을 만족한다고 하자.
p(x0,x1,⋯,xt∣z0,z1,⋯,zt)≈i=1∑nwt(i)δ(x0,x1,⋯,xt−x0(i),x1(i),⋯,xt(i))
우리가 얻고자 하는 것은 이 wt(i)를 구하는 것이다. 중요도 샘플링에 따르면 wt(i)는 다음과 같아야 한다.
wt(i)=qt(x0(i),x1(i),⋯,xt(i))p(x0(i),x1(i),⋯,xt(i)∣z0,z1,⋯,zt)
식이 길어지기 때문에 앞으로는 x0(i),x1(i),⋯,xt(i)를 간단히 x0:t(i)로 표기하겠다. 이 표기법을 사용하면 위 식은 다음과 같이 간단히 표현된다.
wt(i)=qt(x0:t(i))p(x0:t(i)∣z0:t)(2)
이제 우변의 분자를 베이즈 정리를 사용하여 분해할 것이다. 먼저 이 식을 조건부 확률의 정의에 따라 그대로 전개하면
p(x0:t(i)∣z0:t)=p(z0:t)p(x0:t(i),z0:t)
조건부 확률의 정의에 따라 zt만을 따로 빼내면
=p(z0:t)p(zt∣x0:t(i),z0:t−1)p(x0:t(i),z0:t−1)
다시 조건부 확률의 정의에 따라 xt(i)만을 따로 빼내면
=p(z0:t)p(zt∣x0:t(i),z0:t−1)p(xt(i)∣x0:t−1(i),z0:t−1)p(x0:t−1(i),z0:t−1)
분모와 분자를 모두 p(z0:t−1)로 나누면
=p(z0:t)/p(z0:t−1)p(zt∣x0:t(i),z0:t−1)p(xt(i)∣x0:t−1(i),z0:t−1)p(x0:t−1(i),z0:t−1)/p(z0:t−1)
조건부 확률의 정의에 따라
=p(zt∣z0:t−1)p(zt∣x0:t(i),z0:t−1)p(xt(i)∣x0:t−1(i),z0:t−1)p(x0:t−1(i)∣z0:t−1)
이때 이 식의 분모는 상수이므로 생략할 수 있다. 지금 구하는 것은 wt(i)의 분자인데, ∑i=1nwt(i)=1이므로 각 wt(i)의 상대적인 크기만 중요하기 때문이다. 그러므로
p(x0:t(i)∣z0:t)∝p(zt∣x0:t(i),z0:t−1)p(xt(i)∣x0:t−1(i),z0:t−1)p(x0:t−1(i)∣z0:t−1)
여기서 마르코프 체인 가정에 따라 무시할 수 있는 변수들을 소거하면 다음과 같은 결론을 얻는다.
p(x0:t(i)∣z0:t)∝p(zt∣xt(i))p(xt(i)∣xt−1(i))p(x0:t−1(i)∣z0:t−1)(3)
이것이 관측값들이 주어졌을 때 상태가 특정한 궤적을 따를 확률분포다.
중요도 업데이트
다음으로 이를 통하여 중요도 업데이트 식을 유도한다. 식 (3)을 식 (2)에 대입하면
wt(i)∝qt(x0:t(i))p(zt∣xt(i))p(xt(i)∣xt−1(i))p(x0:t−1(i)∣z0:t−1)(4)
식 (4)에 식 (1)을 대입하면
wt(i)∝qt−1(x0:t−1(i))rt−1(i)(xt(i))p(zt∣xt(i))p(xt(i)∣xt−1(i))p(x0:t−1(i)∣z0:t−1)
t−1시간의 항을 묶어내면
wt(i)∝rt−1(i)(xt(i))p(zt∣xt(i))p(xt(i)∣xt−1(i))qt−1(x0:t−1(i))p(x0:t−1(i)∣z0:t−1)
wt(i)의 정의에 따라
wt(i)∝rt−1(i)(xt(i))p(zt∣xt(i))p(xt(i)∣xt−1(i))wt−1(i)
이것이 파티클 필터의 가장 기초적인 업데이트 공식이며, 이것을 Sequential Importance Sampling(SIS)라고 한다.
그리고 일반적으로는 계산량을 줄이기 위해 rt(i)(xt(i))를 적절히 p(xt(i)∣xt−1(i))로 선택한다. 그러면 식이 아래와 같이 간단해진다.
wt(i)∝p(zt∣xt(i))wt−1(i)
SIS에 기반한 파티클 필터의 전체 로직을 pseudocode로 나타내면 다음과 같다.
xs = sample_from_prior()
ws = [1.0] * n_particles
for t in range(1, T):
z = observe()
for i in range(n_particles):
xs[i] = transition(xs[i])
ws[i] *= likelihood(z, xs[i])
ws_sum = sum(ws)
for i in range(n_particles):
ws[i] /= ws_sum
재샘플링(Resampling)
그런데 위 방법을 그대로 사용하면 몇 스텝만에 중요도가 낮은 입자들은 계속 중요도가 낮아져 0에 수렴하고 하나의 입자에 모든 중요도가 몰리게 된다. 이를 퇴화(degeneracy)라고 한다. 퇴화가 발생하면 계산량의 대부분이 확률밀도가 거의 0인 불필요한 계산에 소모될 뿐만 아니라, 입자가 확률분포 전체를 근사하지 못하고 하나의 점만을 나타내게 되면서 필터의 성능이 크게 저하된다.
이에 따라 필터가 퇴화되었을 경우 중요도가 높은 입자들을 복제하고 중요도가 낮은 입자들을 제거하는 재샘플링(resampling)이 필요하다. 이것은 확률분포상 0에 가까워 무의미한 부분에는 샘플 개수를 줄이고 중요한 부분은 조밀하게 샘플링하는 것으로 해석할 수 있다. 다른 관점에서 보면 재샘플링은 중요도 샘플링으로 나타낸 확률분포에서 경험적 샘플링 (empirical sampling)을 수행하는 것과 같다. 그러므로 이것은 나타내고자 하는 확률분포를 변화시키지 않는다.
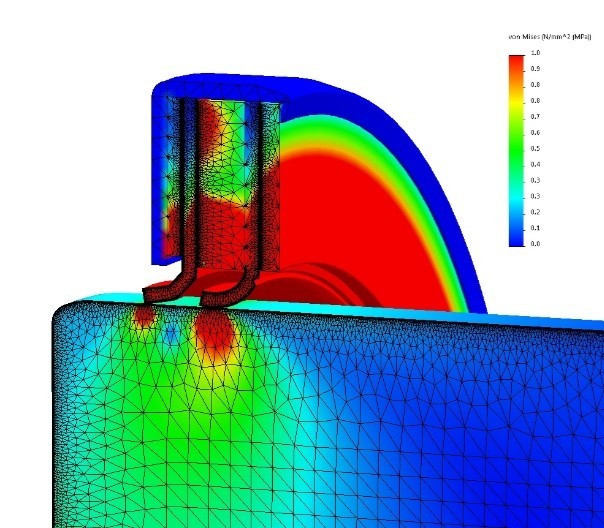
위 이미지는 유한요소해석(Finite Element Analysis)에서 메시의 구성을 나타낸 것이다. 힘을 많이 받는 중요한 부분에는 메시를 조밀하게 할당하고 중요하지 않은 부분에는 메시를 적게 할당하는 것을 볼 수 있다. 이것은 재샘플링의 개념과 유사하다.
재샘플링에는 일반적으로 다음 방법들이 사용된다.
- 다항 재샘플링(Multinomial Resampling): 중요도에 비례하여 입자를 무작위로 샘플링
- 시스템 재샘플링(Systematic Resampling): 중요도에 따라 균일한 간격으로 샘플링
- 계층적 재샘플링(Stratified Resampling): 중요도에 따라 계층을 나누어 각 계층에서 균일하게 샘플링
- 잔차 재샘플링(Residual Resampling): 가중치에 비례하여 샘플링을 수행하고 남은 가중치를 사용하여 추가 샘플링을 수행
다양한 재샘플링 방법이 있으나 다른 방법에 비해 항상 좋은 성능을 보이는 방법은 없다는 것이 알려져 있다. 일반적으로는 구현이 간단한 다항 재샘플링이 많이 사용된다.
재샘플링은 중요도가 높은 입자를 높은 입자를 그대로 복제하기 때문에 재샘플링 직후에는 똑같은 입자가 여러 개 생긴다. 그러나 바로 다음 스텝에서 예측 단계의 importance sampling이 (위 pseudo-code에서 transition 함수) 확률적인 과정이기 때문에 이를 거치며 각 입자들은 서로 달라진다.
재샘플링을 수행하는 시점 역시 다양하다. 가장 간단하게는 매 스텝마다 재샘플링을 수행할 수 있으며, 실제로도 많이 사용된다. 그러나 그 경우 계산량이 많아지는데다 확률분포가 높은 쪽에 모든 입자가 모여 필터의 표현력이 떨어질 수 있다. 따라서 매 스텝이 아닌 특정 간격으로 재샘플링을 수행하게 되는데, 일반적으로 필터가 일정 수준 이하로 퇴화되었을 때 재샘플링을 수행하는 방법이 많이 사용된다.
필터의 퇴화 수준을 판단하는 데는 유효 표본 크기 (effective sample size)가 주로 사용된다.
Neff=∑i=1n(wt(i))21
이것은 실제로는 이상적인 몬테 카를로 샘플링과의 분산 차이를 이용해서 얻어지는 수식이다. 그러나 직관적으로 하나의 샘플만이 가중치를 가지고 나머지가 0이라면 이 값은 1이 되고, 반대로 모든 샘플이 1/n의 가중치를 가지면 이 값은 n이 된다는 것을 알 수 있다. 따라서 이 값이 특정 문턱값 Nth보다 작아지면 필터가 퇴화된 것으로 판단할 수 있다.
유효 표본 크기에 기반한 재샘플링을 반영하여 pseudocode를 수정하면 다음과 같다.
xs = sample_from_prior()
ws = [1.0] * n_particles
for t in range(1, T):
z = observe()
for i in range(n_particles):
xs[i] = transition(xs[i])
ws[i] *= likelihood(z, xs[i])
ws_sum = sum(ws)
for i in range(n_particles):
ws[i] /= ws_sum
if effective_sample_size(ws) < N_th:
xs, ws = resample(xs, ws)
이것이 일반적인 파티클 필터의 구현이다.
구현
아래는 마우스 위치를 추종하도록 간단한 파티클 필터를 구현한 시뮬레이션이다.
위 시뮬레이션에서 빨간색 점은 마우스의 현재 위치를 나타내며, 검은 점은 위치가 알려진 랜드마크를 나타낸다. 시뮬레이션 공간은 각 변이 10m인 정사각형 모양이다. 매 타임스텝마다 현재 마우스 위치로부터 랜드마크까지의 거리가 측정되며 이 측정은 95% 신뢰구간이 1m인 정규분포 노이즈를 포함한다. 파티클 필터는 100개의 입자를 사용하여 이 측정값으로부터 마우스의 위치를 추정한다. 추정값은 하얀색 점으로 표시된다. 재샘플링 방법으로는 다항 재샘플링을 사용하며 Neff<Nth=0.5N 이하이면 재샘플링한다. 시스템 모델은 적당한 정규분포를 사용하였다. 타임스텝은 requestAnimationFrame을 사용하여 보는 사람의 환경에 따라 다를 수 있다.
이 예제는 파티클 필터의 동작 모습을 시각적으로 보여주기 위한 것으로 실용적으로 사용하는 것보다 훨씬 나쁜 값들을 사용하였다. 일반적으로는 1000개 이상의 입자가 사용되며 랜드마크 개수도 훨씬 많고 센서의 오차도 훨씬 작다. 또한 시스템 모델 역시 유저 입력이나 현재 상태(속도 등)을 반영하는 훨씬 정교한 모델이 사용된다.
참고문헌
- Elfring J, Torta E, van de Molengraft R. Particle Filters: A Hands-On Tutorial. Sensors (Basel). 2021 Jan 9;21(2):438. doi: 10.3390/s21020438. PMID: 33435468; PMCID: PMC7826670.
- https://en.wikipedia.org/wiki/Particle_filter
- M. S. Arulampalam, S. Maskell, N. Gordon and T. Clapp, "A tutorial on particle filters for online nonlinear/non-Gaussian Bayesian tracking," in IEEE Transactions on Signal Processing, vol. 50, no. 2, pp. 174-188, Feb. 2002, doi: 10.1109/78.978374.
- Doucet, Arnaud, Simon Godsill, and Christophe Andrieu, 'On Sequential Monte Carlo Sampling Methods for Bayesian Filtering', in Andrew C Harvey, and Tommaso Proietti (eds), Readings In Unobserved Components Models (Oxford, 2005; online edn, Oxford Academic, 31 Oct. 2023), https://doi.org/10.1093/oso/9780199278657.003.0022, accessed 14 Feb. 2024.
- https://en.wikipedia.org/wiki/Importance_sampling
- Bergman, N. (1999). Recursive Bayesian Estimation : Navigation and Tracking Applications (PhD dissertation, Linköping University). Retrieved from https://urn.kb.se/resolve?urn=urn:nbn:se:liu:diva-98184