Translated with the help of ChatGPT and Google Translator
This time, I studied particle filters, which I had been putting off. The purpose of this article is to explain the principles of particle filters in detail so that anyone can understand them.
If you search the Internet, you will find countless articles, including papers, that explain particle filters in detail. However, articles that provide easy explanations only explain important concepts through abstract metaphors without proof. In that case, although it is easy to implement in code, it is difficult to know why it works or does not work, and whether modifying the algorithm will mathematically guarantee optimality.
On the other hand, most articles that explain the content in detail, such as papers, are skipped over without explaining the easy parts. However, the easy part was not at the level of equation expansion or factorization, but could be proven only by applying various complex theorems, so it was often difficult to understand the flow. Moreover, many articles, including Wikipedia and papers, use various notations without explanation, making it difficult to interpret the correct meaning of the expression in the first place.
So, I would like to explain particle filters by including not only abstract concepts but also rigorous mathematical proofs so that even people with only a high school level of mathematical knowledge can understand them.
Specifically, you will need the following background knowledge:
- High school level probability theory (conditional probability, joint probability, Bayes' theorem)
- Concept of integration
Because the content is long, it is organized in written form.
Filter
In order to understand various filters, including particle filters, it is essential to first understand the concept of filters. In signal processing and control engineering, a filter refers to a device or mathematical structure that passes only the desired signal from a signal in which various signals are overlapped.
The reason a filter is needed is because signals inevitably contain noise. From a control or signal processing perspective, all signals are considered the sum of the desired signal and noise. In an ideal environment where signals are transmitted without loss, a filter would be unnecessary, but in reality, noise is included for various reasons, including measurement uncertainty, so a filter is necessary.
The operation of the filter is fundamentally divided into a process of obtaining the signal value and a process of estimating the true value from this. At this time, obtaining the value of the signal is called measurement or observation, and estimating the true value from this is called estimate or *prediction It is said to be *.
Depending on the characteristics of the signal, filters are implemented in various ways. For example, in electronics, the frequencies of signals and noise are often different. From this, the filter is implemented by attenuating everything except the desired frequency band. The most basic of them is the moving average. Moving average estimates the current true value from the (weighted) average of previous measurement values, and can be seen as attenuating high-frequency signals in the frequency domain.
On the other hand, there are cases where it is difficult to distinguish between signal and noise using this method when the system is complex or has large nonlinearity. In such cases, a filter based on probability theory can be used. A stochastic filter approaches the method of calculating the probability distribution of a signal rather than estimating a single true value of the signal. Mathematically, this is expressed as a conditional probability distribution of the true value given the measured values up to the current point as shown below.
When a comma
,is used in a probability distribution, it means a joint probability distribution (). Therefore, the above equation can be interpreted as follows.
Bayes Filter
A Bayes filter is a method of expressing the above probability distribution by combining other probability distributions that are already known. This is because the above equation is simply a mathematical expression of the sentence 'probability distribution of the true value given the measured values', and does not tell us at all how to calculate the probability distribution.
The Bayes filter assumes that the two probability distributions below are already known.
- : Probability distribution of the measured value when the true value is given
- : Probability distribution of the true value given the previous true value
These two probability distributions are called measurement model and system model, respectively, and using these two probability distributions, the probability distribution of the true value can be recursively calculated as follows. .
Below, we explain other concepts necessary to derive the Bayes filter and derive the Bayes filter from them.
Conditional Independence
Since the concept of conditional independence is often used in the derivation of Bayes filters, it is important to understand conditional independence. Conditional independence means that given an event , events and are independent. Below are various expressions for conditional independence, all of which are equivalent.
- : Given , the joint probability distribution of and is It is equal to the product of the probability distribution of $.
- : The above equation is expanded according to the definition of conditional probability.
- : Given , the probability distribution of is not affected by .
- : Given , the probability distribution of is not affected by .
What is important here is that and are independent only when is given. That is, if and are conditionally independent with respect to , and are generally not independent.
Additionally, if two variables are conditionally independent with respect to the other variable , the following important properties hold true.
This equation is called Chapman–Kolmogorov Equation (CKE). More precisely, CKE refers to a more general equation for several random variables, and the above equation can be said to be a special case of CKE that deals with three random variables.
The proof is as follows.
Since and are conditionally independent of ,
Substituting this into the above equation gives
If we expand the right side according to the definition of conditional probability, we get
By the law of total probability
By definition of conditional probability
Markov Chain
When a system satisfies the following properties, it is called a Markov chain.
This indicates that the current state of the system depends only on the state immediately before it and does not depend on other past states. Many systems, including real-world physical phenomena, satisfy this property.
Markov chains can be interpreted in terms of conditional independence. In other words, given , the probability distribution of is conditionally independent with respect to .
Hidden Markov Chain
However, in general, it is impossible to directly measure the entire state of the system, and only part of the system can be measured indirectly. This Markov chain is called a hidden Markov chain.
In the above diagram, the arrow is a state and cannot be measured directly. is the observed value obtained through measurement. The arrow indicates that the random variable depends only on . this can also be interpreted to mean that for any random variable other than , and are conditionally independent of .
Bayes' theorem
Bayes' theorem states that the following relationship holds true for conditional probability.
Bayes' theorem can be interpreted in two ways:
- Inverse probability problem: Finding given
- Example) Given the probability of testing positive when having a disease, finding the probability of being sick when testing positive is given.
- Posterior probability estimation: updating the prior probability to a more accurate probability through the measured value
- Example) In general, you know the probability of contracting a certain disease, but when you learn new test results, you recalculate the probability of contracting the disease.
Bayes filter uses Bayes' theorem in terms of posterior probability estimation. In other words, the measured value is reflected in the previously known probability distribution and updated to a more accurate probability distribution is repeated.
Derivation of Bayes filter
If we recall again the probability distribution we want to find, it is as follows.
To calculate this, assume that you know the two probability distributions below.
- : system model
- : measurement model
From this, Bayes' filter is derived by applying Bayes' theorem as follows.
First, if you apply Bayes' theorem to the equation you want to find,
At this time, depends only on according to the assumption of the hidden Markov chain, so it is conditionally independent with respect to any random variable other than . That is, the following holds true.
From this, if we set ,
Applying this again to Bayes' theorem, we get
However, according to the definition of conditional probability, , so
Divide the denominator and numerator by , respectively.
At this time, the denominator is decomposed by CKE, which was previously discussed in the conditional independence section, as follows.
Substituting this back into the equation, we get:
The unknown part of this equation is . At this time, according to the assumption of the Markov model, depends only on , so is conditionally independent from am. Therefore, it is similarly decomposed by CKE as follows.
At this time, the unknown part of this equation, , is the original expression . From this, the following recursive estimation can be performed.
- Assume you know .
- Calculate from this. Since this calculates the probability distribution of the true value at time based on information up to time , this process is called estimation or prediction (prediction).
- Calculate from this. This process is called update because it recalculates the probability distribution of the true value by reflecting the new measured value in the estimated value.
When you first start calculating, an initial estimate is needed. is a probability distribution in the case where there is no information, so a uniform probability distribution or normal distribution can be used. The more precise the initial estimate is used, the more accurate the subsequent estimate becomes.
The method of estimating the probability distribution of the true value as shown above is called Bayes filter and is the theoretical basis for all probabilistic filtering.
However, Bayesian filters must perform integration during the prediction process, but integration of non-linear or numerically defined functions is often very difficult or sometimes impossible. Therefore, in general, Bayes filters cannot be directly applied to real-world problems, and various methods to approximate them have been proposed.
Methods for approximating arbitrary probability distributions are largely divided into parametric methods and nonparametric methods. The parametric method is a method of estimating the parameters of the model assuming that the probability distribution follows a specific type of probability distribution. This can be used when there is a theoretical basis for the probability distribution. On the other hand, the non-parametric method is a method of approximating the probability distribution using measured values without making any assumptions about the probability distribution.
Kalman filter is an approximation to the Bayes filter through a parametric method, and is a method that allows integrals to be solved analytically by assuming that the linearity and error of each model are normal distribution. The Kalman filter provides very accurate estimates when the amount of calculation is not large and linearity and normal distribution assumptions are satisfied. However, if important assumptions such as linearity are not satisfied, the filter may diverge.
Particle filter, which will be discussed later, is a non-parametric approximation to the Bayes filter and is a method of approximating the Bayes filter using Monte Carlo sampling. Particle filters make no assumptions about the model, so they can be used even when assumptions such as linearity are not met. However, since it is an approximation through sampling, it has the disadvantage that the calculation amount is large and the accuracy may be low.
Particle Filter
It was previously said that the Bayes filter estimates the probability distribution of the true value by repeating the following two steps.
- prediction
- update
However, in general, a system is a two-dimensional or more vector, and the system model is given as a matrix equation. Therefore, the integration in the prediction step becomes multiple integrations in high dimensions, and the integration area can become very complicated.
Empirical Distribution Function
In this case, the integral can be approximated using an empirical distribution function. The empirical distribution function is a method of approximating the probability distribution by sampling the measured values when it is difficult to directly obtain the value of a probability distribution function but easy to sample. At this time, when the number of samples becomes sufficiently large, the distribution of samples converges to the original probability distribution. Mathematically, this can be expressed as follows.
At this time, is a value sampled from the probability distribution , is the Dirac-delta function, , and (). The integral of the Dirac-delta function becomes 1. Alternatively, the above equation can be integrated and expressed in the form of a cumulative distribution function as shown below.
In this case, is a function that is 1 when , and 0 otherwise.
Below is an empirical distribution function calculated using samples sampled from a normal distribution. 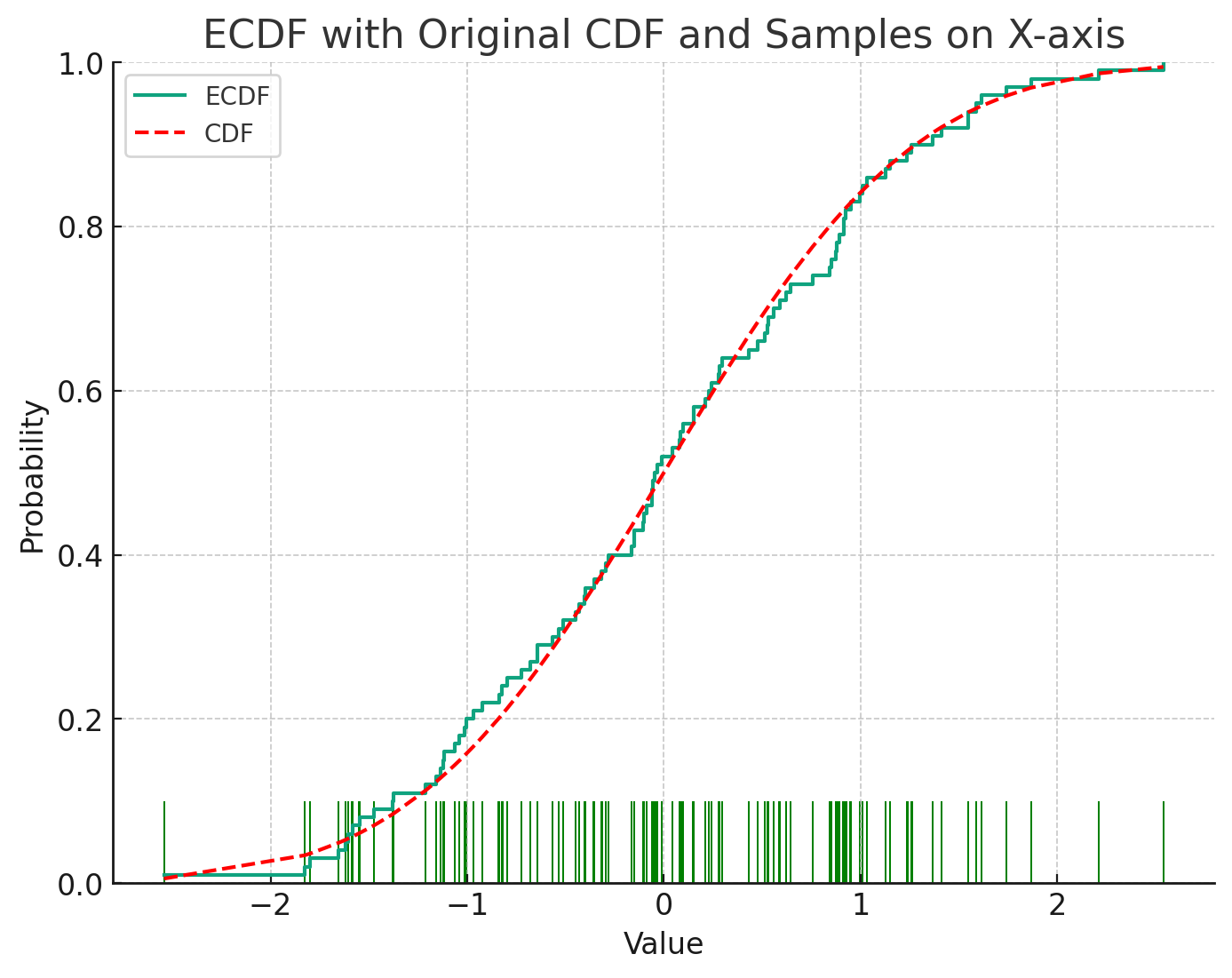
Importance Sampling
However, there is a problem that in order to obtain the empirical distribution function through simulation rather than real-life experiment, the original probability distribution must be known. In other words, an attempt was made to use empirical sampling to obtain the probability distribution, but a paradoxical problem arises in that the original probability distribution must be known in order to do so.
At this time, even if sampling is not possible from the original probability distribution, the probability distribution can be approximated through sampling by using importance sampling. Importance sampling is a method of sampling from another probability distribution and using it to approximate the expected value of , even if the probability distribution is not known, as follows.
Below is an approximation of the cumulative probability density function of the normal distribution using importance sampling from the uniform probability distribution.
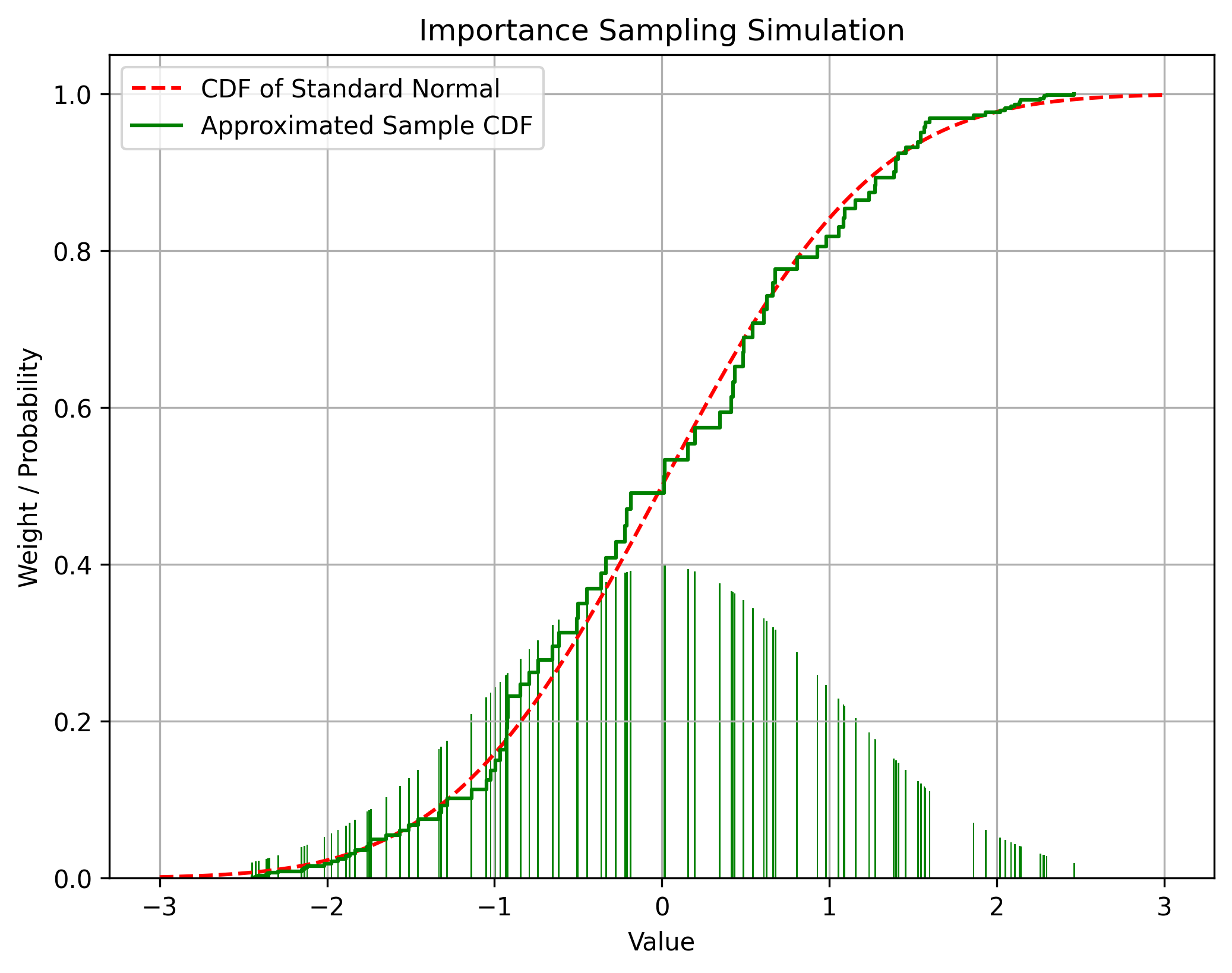
At this time, the probability distribution on which sampling is performed is called the importance distribution or proposal distribution. The proposed distribution can select an arbitrary probability distribution with non-zero values where the probability density of the original distribution is greater than 0, but the more similar the original distribution is, the higher the approximation accuracy. The proposed distribution generally uses a normal distribution or uniform distribution that is easy to sample.
However, it should be noted that the mean of the probability distribution obtained as a result of importance sampling converges to the original probability distribution, but the variance is different from the original probability distribution.
Sequential Importance Sampling
Particle filters approximate Bayesian filters using importance sampling, as mentioned earlier. This is called Sequential Importance Sampling (SIS). The proof of SIS is a bit complicated. First, when each particle moves along a specific probability distribution over time, we will obtain the probability distribution of the trajectory itself and then show that it is also the same as the probability distribution of the particle.
In general, if you look at other articles, in this calculation, all proposed probability distributions are expressed with a single symbol, . However, in this article, different probability distributions will be assigned different symbols to avoid confusion. The symbol generally represents the probability distribution of a random variable, and other symbols represent specific probability distributions. These should not be confused.
Probability distribution of particle trajectories
First, extract samples from the initial probability distribution . Obviously, .
And let us assume that each particle moves according to the probability distribution over time. .
Where a particle will be at the next instant generally depends on where it was at the previous instant. Therefore, although not explicitly stated, is generally dependent on .
Then, for each particle , the probability that the particle is initially at and at the next instant is at is same.
Expanding, the probability that each particle moves along the trajectory over time is as follows.
At this time, let the probability distribution of the particle trajectory at time be . Then is expressed as follows.
Expressing this in ignition form is as follows.
This is the probability distribution that each particle moves along a specific trajectory over time.
Probability distribution of state trajectory
Next, the probability distribution of the original state that we want to obtain is as follows.
This is slightly different from the probability distributions discussed earlier. Previously, we discussed the probability distribution of the current state given the observed values up to the current point. However, this includes all probability distributions of states at previous times, given the observations up to the current point.
At this time, let us assume that there is an appropriate weight so that the probability distribution of the particle approximates the probability distribution to be obtained according to the principle of importance sampling. In other words, let’s say the following conditions are satisfied.
What we want to achieve is to find this . According to importance sampling, should be:
Since the expression is long, from now on, will be simply called I will mark it. Using this notation, the above equation is simply expressed as follows.
Now we will decompose the molecule on the right side using Bayes' theorem. First, if we expand this equation according to the definition of conditional probability, we get
According to the definition of conditional probability, if we take out only ,
Again, according to the definition of conditional probability, if we take out only ,
Divide both the denominator and numerator by
According to the definition of conditional probability
At this time, the denominator of this equation is a constant, so it can be omitted. What we are looking for now is the numerator of , and since , the relative size of each Because it's only important. therefore
Here, if we eliminate variables that can be ignored according to the Markov chain assumption, we get the following conclusion.
This is the probability distribution that a state will follow a certain trajectory given the observations.
Importance Updates
Next, the importance update equation is derived through this. Substituting equation (3) into equation (2), we get
Substituting equation (1) into equation (4), we get
If we bundle the terms of time , we get
According to the definition of
This is the most basic update formula for particle filters, and it is called Sequential Importance Sampling (SIS).
And in general, to reduce the amount of calculation, is appropriately changed to $p(xt^{(i)} | x{t-1}^{(i) }) Select with $. Then, the equation becomes simple as follows.
The entire logic of the SIS-based particle filter is expressed in pseudocode as follows.
xs = sample_from_prior()
ws = [1.0] * n_particles
for t in range(1, T):
#Observation
z = observe()
for i in range(n_particles):
#Prediction
xs[i] = transition(xs[i])
#Update
ws[i] *= likelihood(z, xs[i])
# Normalize
ws_sum = sum(ws)
for i in range(n_particles):
ws[i] /= ws_sum
Resampling
However, if the above method is used as is, the importance of particles with low importance continues to decrease and converges to 0 in just a few steps, and all importance is concentrated on one particle. This is called degeneracy. When degeneracy occurs, not only is most of the calculation amount consumed in unnecessary calculations where the probability density is almost 0, but the filter performance is greatly reduced as the particles do not approximate the entire probability distribution and only represent a single point.
Accordingly, when the filter is degraded, resampling is necessary to replicate particles of high importance and remove particles of low importance. This can be interpreted as reducing the number of samples in meaningless parts that are close to 0 in the probability distribution and densely sampling important parts. From another perspective, resampling is the same as performing empirical sampling from the probability distribution represented by importance sampling. Therefore, this does not change the probability distribution it is intended to represent.
The image above shows the composition of the mesh in Finite Element Analysis. You can see that a dense mesh is allocated to important parts that receive a lot of force, and a small mesh is allocated to unimportant parts. This is similar to the concept of resampling.
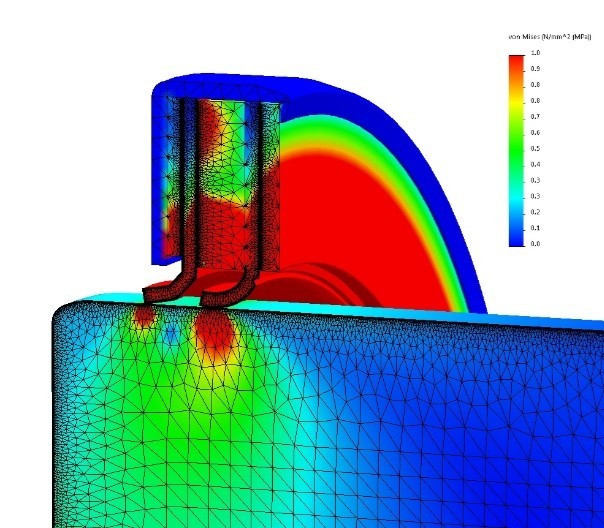
The following methods are generally used for resampling:
- Multinomial Resampling: Randomly samples particles in proportion to their importance
- Systematic Resampling: Sampling at even intervals according to importance
- Stratified Resampling: Divide into layers according to importance and sample uniformly from each layer.
- Residual Resampling: Perform sampling in proportion to the weight and perform additional sampling using the remaining weight.
There are various resampling methods, but it is known that no method always shows better performance than other methods. In general, polynomial resampling, which is simple to implement, is often used.
Because resampling replicates high-importance particles as they are, several identical particles are created immediately after resampling. However, since the importance sampling in the prediction step in the very next step (the transition function in the pseudo-code above) is a stochastic process, each particle becomes different.
The timing of performing resampling also varies. The simplest way is to perform resampling at every step, and it is often used in practice. However, in that case, the amount of calculation increases and all the particles are gathered in the high probability distribution, which may reduce the expressiveness of the filter. Therefore, resampling is performed at specific intervals rather than at every step. In general, a method of performing resampling when the filter has degenerated below a certain level is often used.
The effective sample size is mainly used to determine the level of filter degradation.
This is actually a formula obtained by using the variance difference from ideal Monte Carlo sampling. However, intuitively, if only one sample has a weight and the rest are 0, this value becomes 1, and conversely, if all samples have a weight of , this value becomes . Therefore, if this value becomes smaller than a certain threshold , the filter can be judged to be degenerated.
If the pseudocode is modified to reflect resampling based on the effective sample size, it is as follows.
xs = sample_from_prior()
ws = [1.0] * n_particles
for t in range(1, T):
#Observation
z = observe()
for i in range(n_particles):
#Prediction
xs[i] = transition(xs[i])
#Update
ws[i] *= likelihood(z, xs[i])
# Normalize
ws_sum = sum(ws)
for i in range(n_particles):
ws[i] /= ws_sum
#Resampling
if effective_sample_size(ws) < N_th:
xs, ws = resample(xs, ws)
This is an implementation of a typical particle filter.
Implementation
Below is a simulation that implements a simple particle filter to follow the mouse position.
In the simulation above, the red dot represents the current location of the mouse, and the black dot represents a landmark whose location is known. The simulation space is square-shaped with each side being 10 m. At every time step, the distance from the current mouse position to the landmark is measured, and this measurement includes normally distributed noise with a 95% confidence interval of 1 m. The particle filter uses 100 particles to estimate the mouse's position from these measurements. Estimates are indicated by white dots. Polynomial resampling is used as a resampling method, and resampling is performed if or less. The system model used an appropriate normal distribution. The timestep may vary depending on the viewer's environment using requestAnimationFrame.
This example is intended to visually demonstrate the behavior of a particle filter, and uses much worse values than would be practical. Typically, more than 1,000 particles are used, the number of landmarks is much larger, and the sensor error is much smaller. Additionally, a much more sophisticated system model is used that reflects user input or current status (speed, etc.).
references
- Elfring J, Torta E, van de Molengraft R. Particle Filters: A Hands-On Tutorial. Sensors (Basel). 2021 Jan 9;21(2):438. doi: 10.3390/s21020438. PMID: 33435468; PMCID: PMC7826670.
- https://en.wikipedia.org/wiki/Particle_filter
- M. S. Arulampalam, S. Maskell, N. Gordon and T. Clapp, "A tutorial on particle filters for online nonlinear/non-Gaussian Bayesian tracking," in IEEE Transactions on Signal Processing, vol. 50, no. 2, pp. 174-188, Feb. 2002, doi: 10.1109/78.978374.
- Doucet, Arnaud, Simon Godsill, and Christophe Andrieu, 'On Sequential Monte Carlo Sampling Methods for Bayesian Filtering', in Andrew C Harvey, and Tommaso Proietti (eds), Readings In Unobserved Components Models (Oxford, 2005; online edn, Oxford Academic, 31 Oct. 2023), https://doi.org/10.1093/oso/9780199278657.003.0022, accessed 14 Feb. 2024.
- https://en.wikipedia.org/wiki/Importance_sampling
- Bergman, N. (1999). Recursive Bayesian Estimation: Navigation and Tracking Applications (PhD dissertation, Linköping University). Retrieved from https://urn.kb.se/resolve?urn=urn:nbn:se:liu:diva-98184