Translated with the help of ChatGPT and Google Translator
A line sensor is a sensor used in a line tracer type robot. It is used to estimate the position of a line relative to the center of the sensor so that the robot can follow the line.
Line sensors can be implemented in various forms. Here, we deal with an algorithm that estimates the position of the line when using multiple Infrared (IR) sensors in a row, as shown in the example below.
IR0---IR1---IR2---IR3---IR4---IR5---IR6---IR7
Before discussion, let's define the position of IR0 as -1 and the position of IR7 as 1 for each IR sensor's position . That is, let's say .
Existing algorithm
The robot club I work in, [Zetin] (https://zetin.uos.ac.kr), estimated the position of the line using a weighted average as shown below.
Regarding the sensor value , let's say that the sensor value is 0 when it detects a black background with nothing, and that the value is 1 when the sensor goes exactly above the white line. The value of the sensor located at the border of the line is between 0 and 1.
At this time, previously, the position of the line was estimated by giving weight to the sensor value as follows.
Although this method is very simple, it can lead to greatly incorrect estimates of line position if noise is included. To improve this, I implemented an algorithm to estimate line position using Bayes' theorem.
Bayes' theorem
Bayes' theorem is as follows.
In this equation
- is the prior probability,
- is the posterior probability,
- Likelihood of ,
- is called evidence.
At this time, if is an event that depends on , it is organized as follows using the law of overall probability.
If the distribution is a continuous probability distribution, it is expressed as follows.
Line estimation using Bayes’ theorem
What we want to know is the position of the line given the values of the 8 sensors. To do this, we will obtain the probability density function for the line position and select the value with the highest value. Since this probability density estimates the distribution of sensor positions given sensor values, it is expressed as the conditional probability . However, since we do not know this conditional probability, we will obtain this probability distribution using Bayes' theorem of continuous probability distribution summarized earlier as shown below.
In this equation, in order to determine the prior probability , the distribution of sensor values must be measured. Since the line-following robot follows the line position to 0, the actual sensor value will have a distribution centered on 0. However, here, for general purpose, let us assume a uniform distribution in an appropriate range instead of this assumption. In this case, this range can be slightly larger than , because the sensor can detect the line even if the line is slightly outside the outermost sensor. (This is also a difference from the existing algorithm. In the existing algorithm, the position of the line is always within .)
That is, within that range, . Accordingly, the equation is transformed as follows.
From this, you can immediately estimate the probability distribution by simply finding . And since the denominator of the above equation is a constant, finding that maximizes the above equation is the same as finding that maximizes .
As mentioned above, in Bayes' theorem, is called likelihood. Therefore, this method is called Maximum Likelihood Estimation (MLE).
However, the maximum likelihood method usually assumes that random variables are sampled from the same probability distribution. However, in this case, the probability distribution of values is different depending on the sensor location, so it is different from the general maximum likelihood method. However, since estimating the parameter - in this case the line position - is fundamentally the same as maximizing the likelihood, it would be safe to call this approach the maximum likelihood method.)
To find this, we will obtain the probability distribution of the sensor value according to the distance between the line and the sensor for one sensor, and then expand this to the probability distribution for the sensor value vector.
First, let's denote the probability distribution that the sensor value is for a sensor away, that is, the probability density function, as . At this time, the reason why it appears as a probability distribution rather than a single value is due to noise. Let us assume that these noises are independent of each other. (In reality, there are noise sources (external light, etc.) that have a similar effect on all sensors, so they will not be independent, but it is safe to assume that they are independent.) Then, the probability distribution for the sensor value vector. is expressed as follows:
in other words,
- When the position of the line is given
- From this, the probability density function of each sensor value expected is
- Probability density obtained by inputting actual sensor values
- Expressed as a product.
To check whether this is the correct probability distribution, check whether the integral is 1. According to Pubini's theorem, it can be shown that it becomes 1 as follows.
Pubini's theorem is the theorem that in Riemann integral, if is continuous for a square area , the equation below holds true.
From this, if is expressed as the product of two functions , the equation below is established.
This can be easily extended to higher dimensions.
Therefore, if you substitute the obtained into the above equation, it is organized as follows.
From this, what we want to know is that maximizes this value. At this time, the denominator of this equation is a constant, so maximizing it is the same as maximizing the numerator. Therefore, it is organized as follows.
The above equation is obtained by multiplying the probability density function several times, so the number may be very large or small. Therefore, log transformation is performed and summarized as follows.
Experiment
We implemented this in Python and experimented with it. For the experiment, the probability density function of the sensor value according to distance was defined as follows.
If the actual line position is set to 0.64, the sensor value is measured as follows. 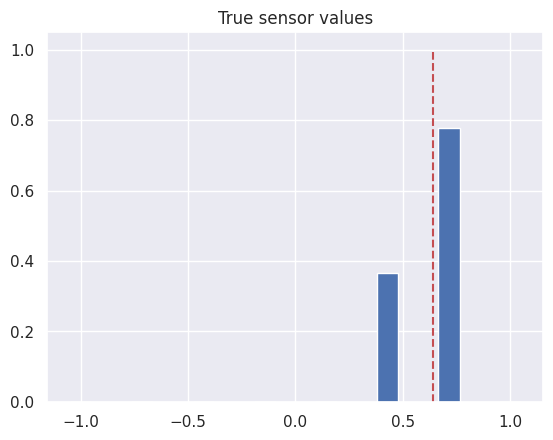
However, since real sensors inevitably contain noise, normal distribution noise was added. 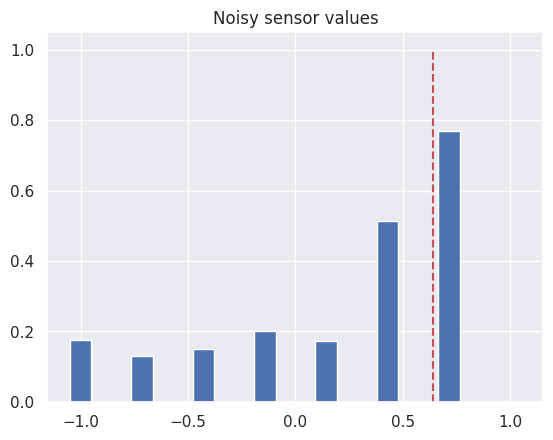
From this, the line position can be estimated as follows. 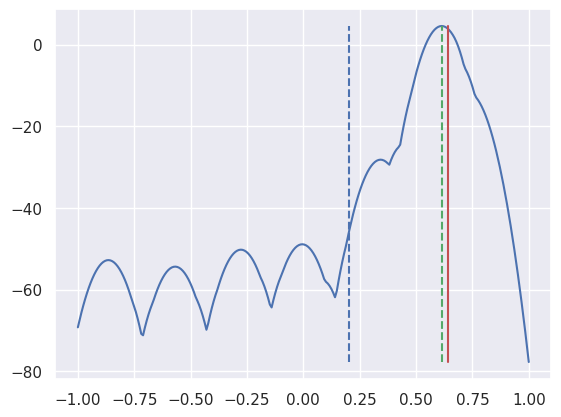
- The red solid line indicates the actual line position.
- The blue curve represents the log likelihood of the expected line position.
- The green dotted line indicates the line position estimated from this.
- The blue dotted line represents the line position estimated from the old algorithm.
This shows that the new algorithm estimates the line position more accurately than the existing algorithm.
optimization
Since this uses multiple exponential and logarithmic operations, the amount of calculation may be too large to be calculated in an embedded system. And since the value may be very small, errors may occur due to floating point calculations.
At this time, this can be optimized by making the following assumptions.
- Assume that the probability density function of sensor values is normal distribution.
- The mean of the distribution is a function of line position.
- The standard deviation of the distribution is a constant.
- Sensor values are independent between sensors.
From these assumptions, let the mean of the sensor value distribution for the distance between the sensor and the line be and the standard deviation be . Then, the probability density function of the sensor value is organized as follows.
Next, let the location of each sensor be and the measured sensor value be . Then is organized as follows.
Therefore, the log likelihood obtained by taking the logarithm of this equation is summarized as follows.
However, what we want to find is that maximizes this equation. Therefore, if we ignore the constant term and constant product, it can be summarized as follows. (Note that argmax is changed to argmin by changing the sign.)
From this, we can confirm that this equation is independent of the standard deviation of the sensor.
To summarize, it can be applied to actual robots as follows. First, perform the following in the tuning step:
- Measure the sensor value by changing the distance between the sensor and the line. At this time, measurements are made by applying various noises, such as providing external light at one location or slightly changing the angle of the line.
- Find the function that represents the average of according to . The best thing is to obtain a physical model based on the distance between the sensor and the line and then tune the parameters according to the actual measured values. However, it would also be okay to simply linearly interpolate the actual measurements or curve fit an appropriate curve.
From this, the inference step performs the following:
- Find the measured sensor value .
- Iterate through the possible values and calculate that maximizes . ( is the location of the sensor.)
- This is very simple and can be fully implemented in C language, etc.
- Additionally, through this optimization, the calculation that previously took about 1.14 seconds could be reduced to 0.0004 seconds.
- Because logarithms or exponents are not used in calculations, less precise operations can be used than floating point numbers. If the range is adjusted appropriately, it can be sufficiently implemented with integer arithmetic.
Below is an implementation of this in Python.
import numpy as np
def mu(ds):
ds = 1-np.abs(ds)*3
ds = np.maximum(ds,0)
return ds
def optimized(values,positions,mu,xs):
n = len(values)
result = np.zeros(len(xs))
for i in range(n):
result += (values[i]-mu(xs-positions[i]))**2
return result
vs = [ ... ] # measured sensor values
ps = np.linspace(-1,1,8) # sensor positions
xs = np.linspace(-1,1,300) # candidate positions
ys = optimized(vs,ps,mu,xs) # log likelihood
x_hat = xs[np.argmin(ys)] # estimated position
Below is a visualization of the results of the above code. Likewise, the solid red line represents the actual line position, and the green dotted line represents the line position estimated from this. (The sensor values used are different from above.) 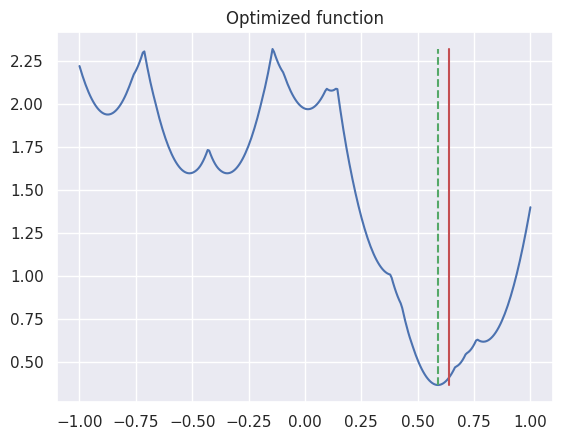
conclusion
- An algorithm was implemented to estimate the position of the line sensor using Bayes' theorem.
- Through this, it was possible to estimate the line position more accurately than the existing algorithm.
- Also, by optimizing this, we were able to reduce the amount of calculation.